位置匹配
:::note 再次强调, 正则表达式是匹配模式, 要么匹配字符, 要么匹配位置.请记住这句话
然而大部分人学习正则时, 对于匹配位置的重视程度没有那么高 :::
什么是位置
位置是相邻字符之间的位置.例如, 下图中箭头所指的地方
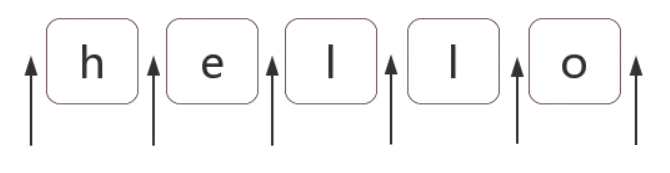
如何匹配位置
共有6个锚字符
^, $, \b, \B, (?=p), (?!p)
前两个
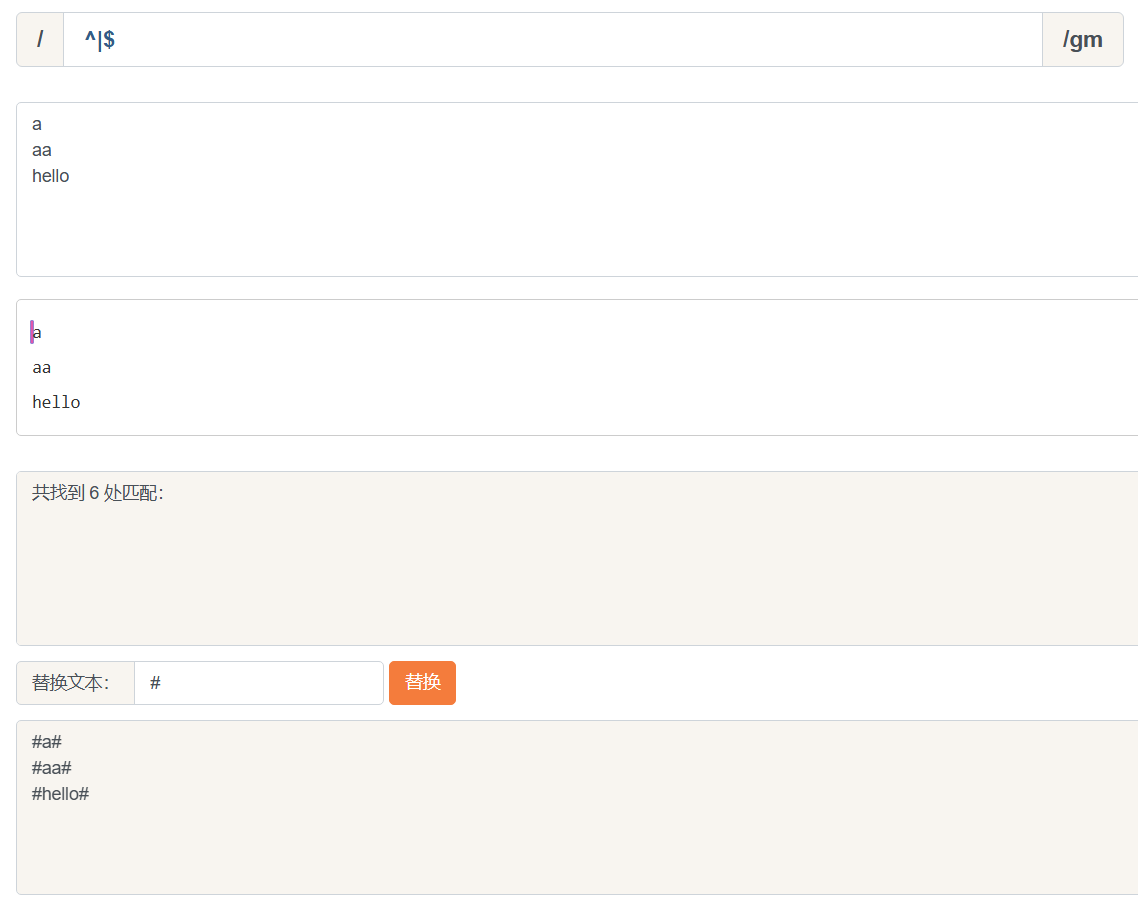
^(脱字符)匹配开头, 在多行匹配中匹配行开头
$(美元符号)匹配结尾, 在多行匹配中匹配行结尾
中间两个
\b是单词边界, 具体就是\w和\W之间的位置, 也包括\w和^之间的位置, 也包括\w和$之间的位置
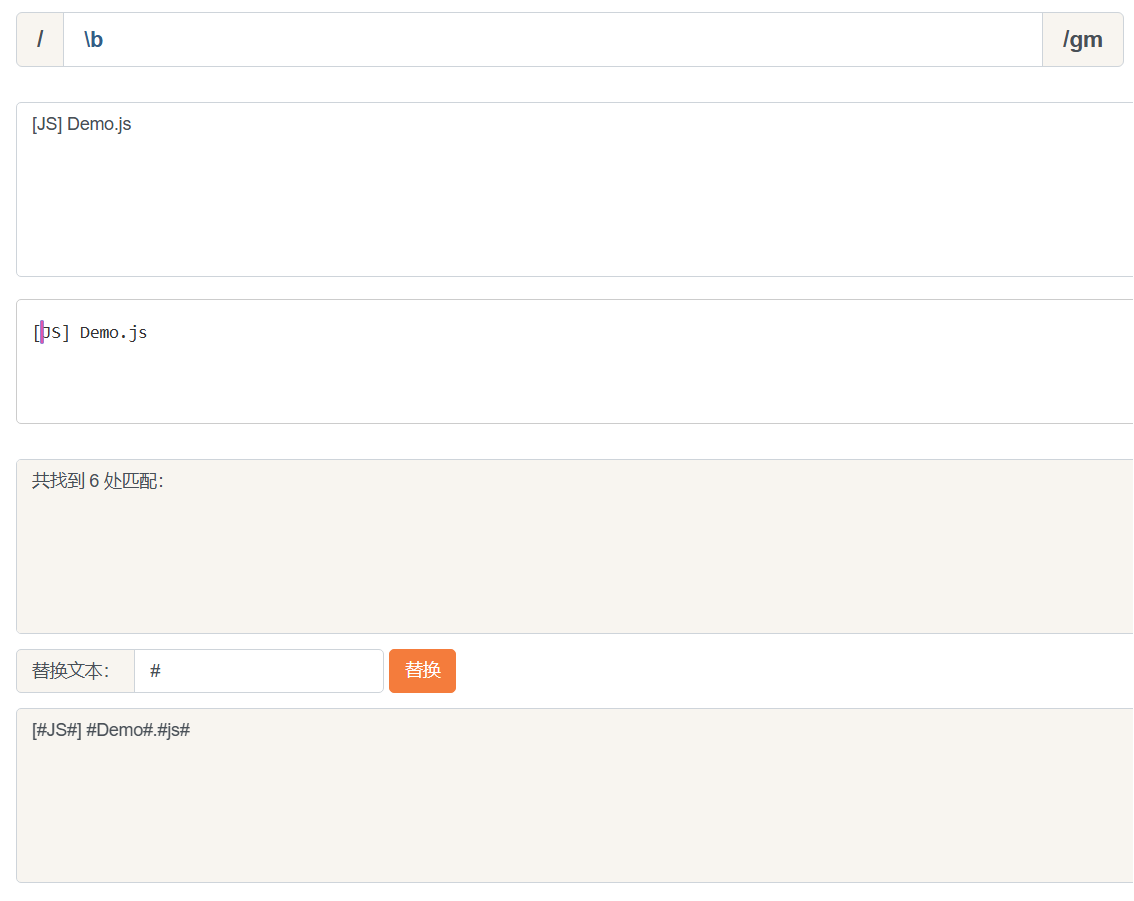
比如一个文件名是[JS] Demo.js中的\b
为什么是这样呢?仔细看看呢~
首先, 我们知道, \w是字符组[0-9a-zA-Z_]的简写形式, 即\w是字母数字或者下划线的中任何一个字符.而\W是排除字符组[^0-9a-zA-Z_]的简写形式, 即\W是\w以外的任何一个字符
此时我们可以看看[#JS#] #Demo#.#js#中的每一个#是怎么来的
- 第一个
#, 两边是[与J, 是\W和\w之间的位置 - 第二个
#, 两边是S与], 也就是\w和\W之间的位置 - 第三个
#, 两边是空格与D, 也就是\W和\w之间的位置 - 第四个
#, 两边是o与., 也就是\w和\W之间的位置 - 第五个
#, 两边是.与j, 也就是\W和\w之间的位置 - 第六个
#, 其对应的位置是结尾, 但其前面的字符s是\w, 即\w和$之间的位置
知道了\b的概念后, 那么\B也就相对好理解了
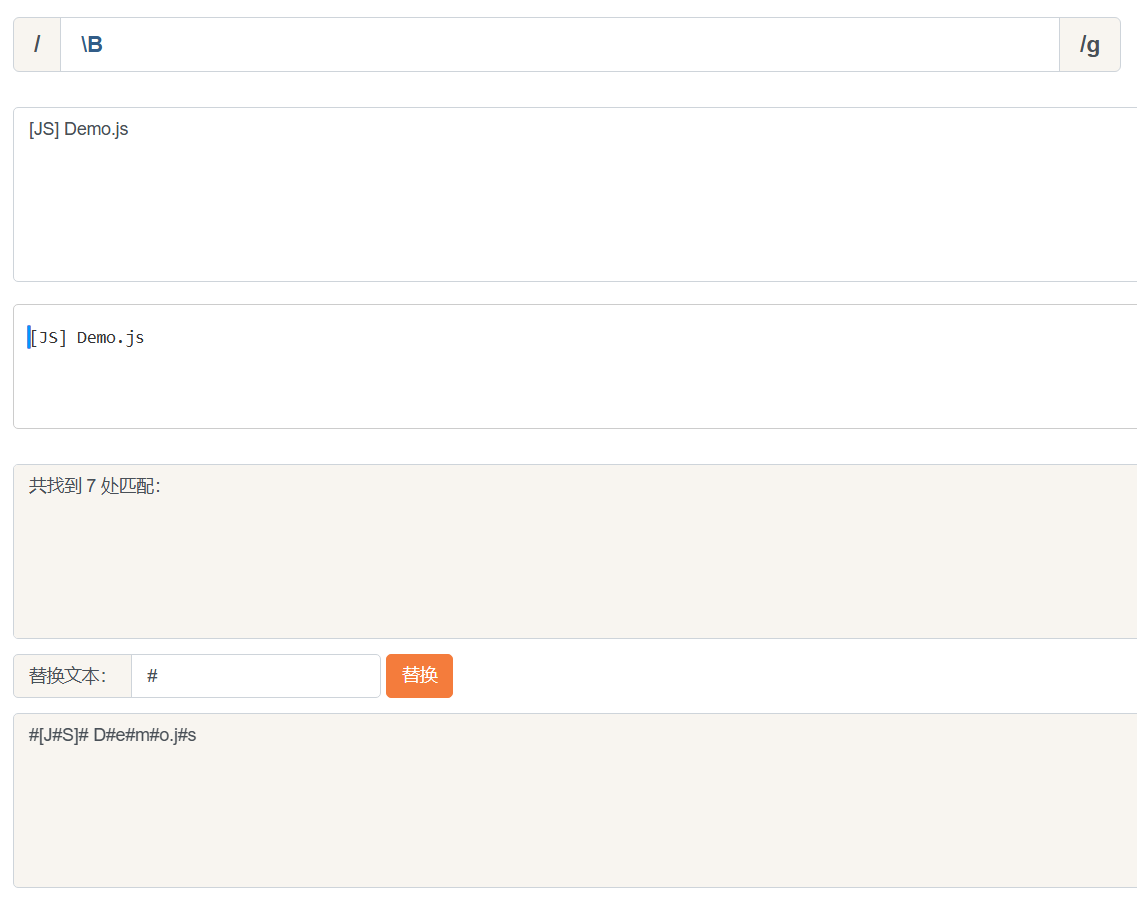
\B就是\b的反面的意思.非单词边界/例如在字符串中所有位置中.扣掉\b.剩下的都是\B的
具体说来就是\w与\w, \W与\W, ^与\W, \W与$之间的位置
比如上面的例子, 把所有\B替换成#
后两个
(?=p), 其中p是一个子模式, 即p前面的位置
比如(?=l), 表示l字符前面的位置, 例如
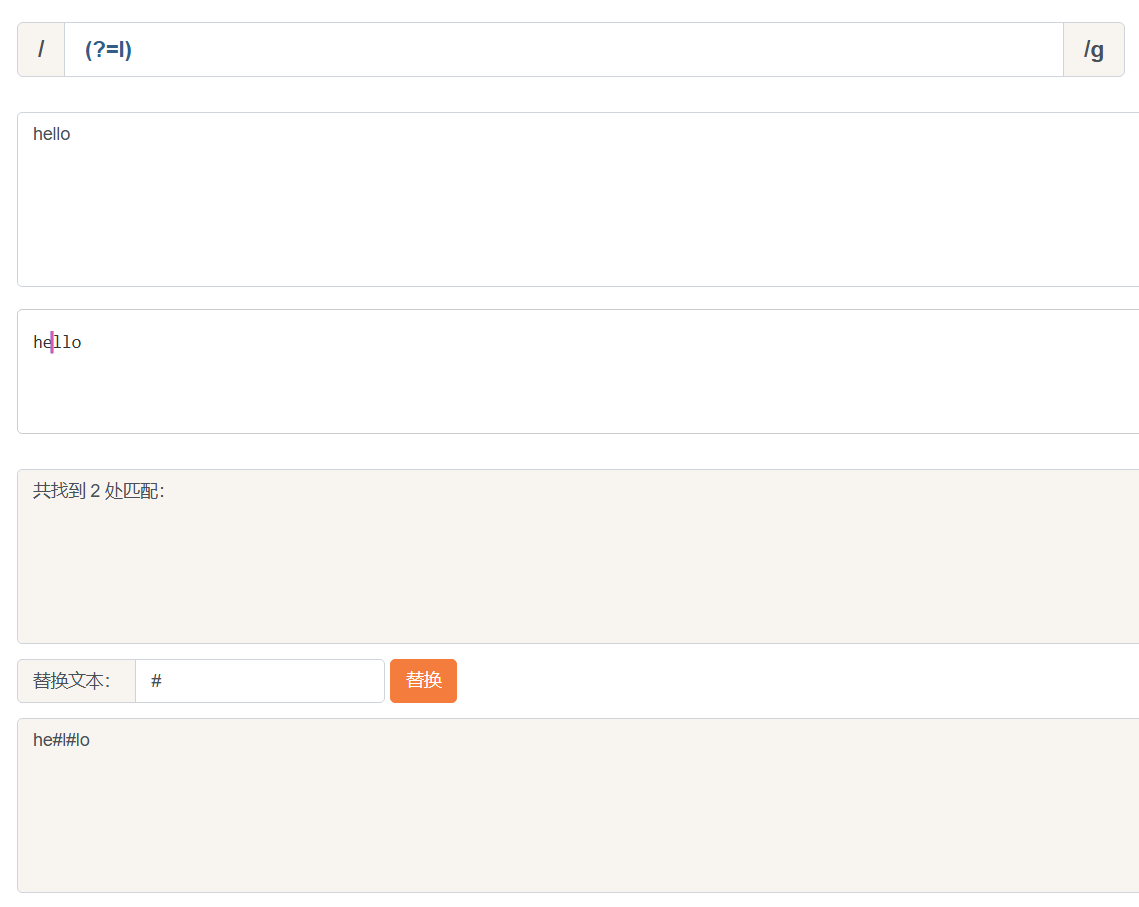 而
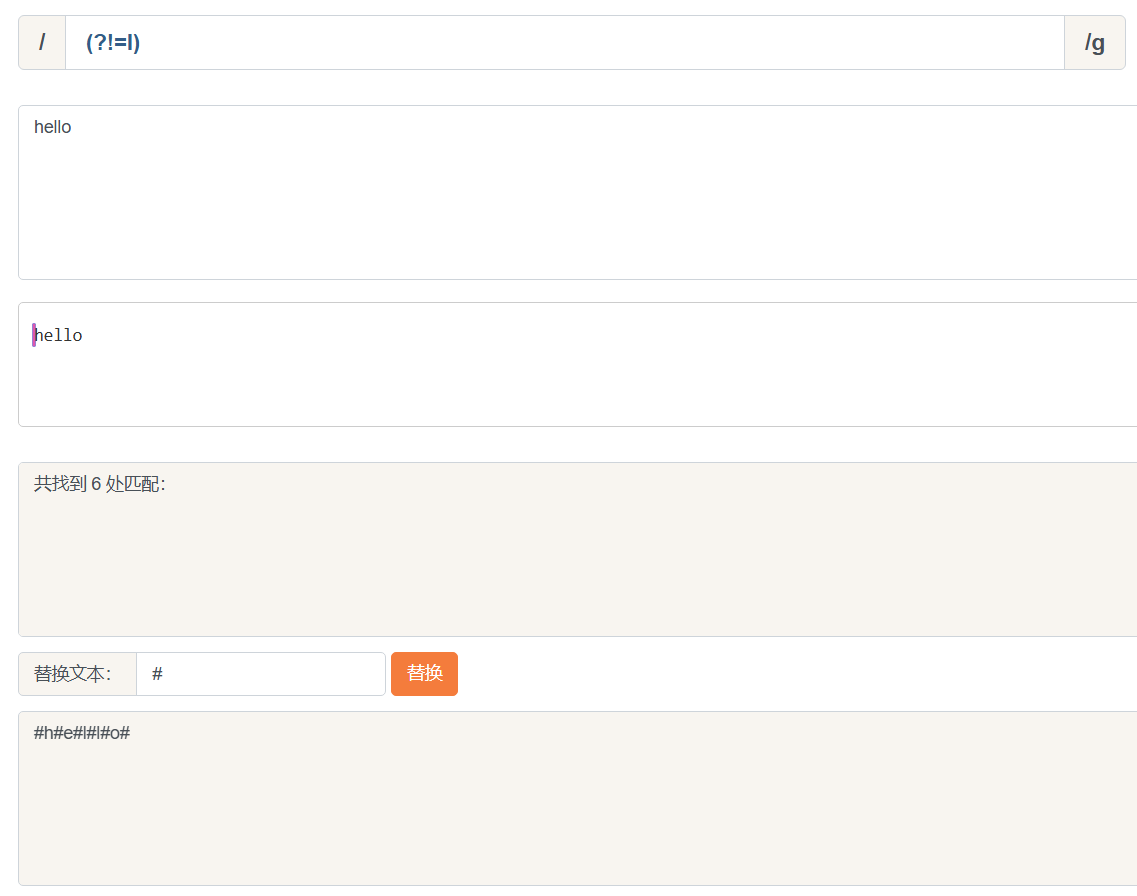
而(?!p)就是(?=p)的反面意思
位置的特性
对于位置的理解, 我们可以理解成空字符 ""
比如"hello"字符串等价于如下的形式
"hello" == "" + "h" + "" + "e" + "" + "l" + "" + "l" + "o" + "";
也就是
"hello" == "" + "" + "hello"
因此, 把/^hello$/写成/^^hello?$/, 是没有任何问题的
:::note 如果你想写屎山代码, 甚至可以写成更复杂
/(?=he)^^he(?=\w)llo$\b\b$/
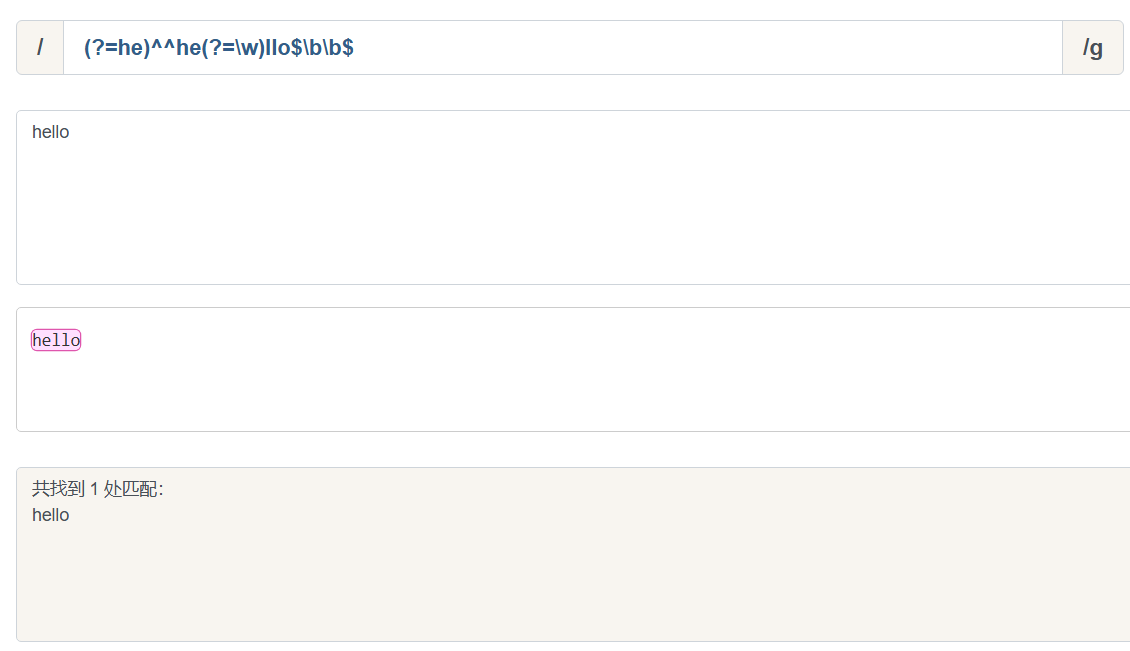 :::
:::
也就是说字符之间的位置, 可以写成多个
把位置理解空字符, 是对位置非常有效的理解方式